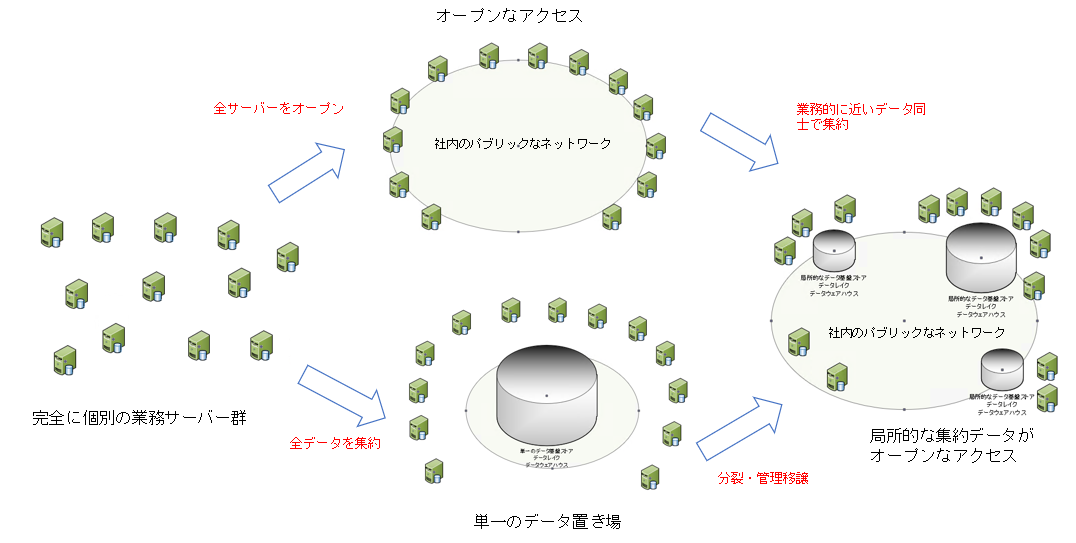
こちらの局所集約が分散したアーキテクチャ (メッシュ アーキテクチャ) になるには、おそらく2通りのアプローチが考えられえます。
① まずは完全分散のデータ共有基盤を作り、それらが意味のある単位で集約していく
② まずは完全統一のデータ共有基盤を作り、それらが崩壊するようにして分裂していく
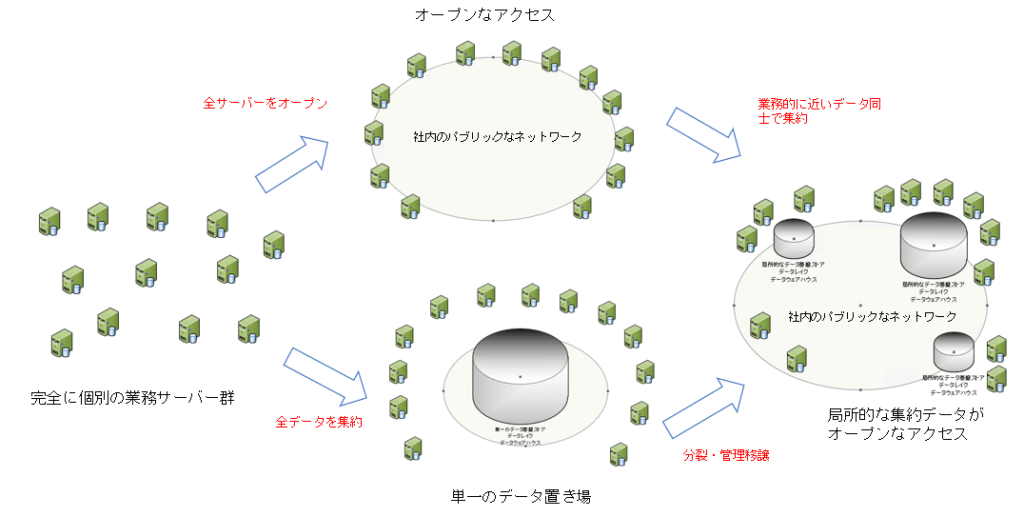
いきなり最終ステップのメッシュ型になることはないでしょう。(IT ベンダーはなぜか最終形だけ提示しドヤ顔します)
巨大な組織の場合、すべての業務を熟知している人はまれです。そして、その人がデータ基盤構築のプロジェクトに参加しているとは限りません。参加していても、IT アーキテクトに対して主導をとれるとは限りません。また、クラスタを作る単位を正確に知ることは困難です。
極端な設計から、実現時の障害を経て、自然に安定した構造に移っていくように、最終的なメッシュ アーキテクチャに落ち着くことがごくごく自然な成り行きと言えます。
完全分散コース
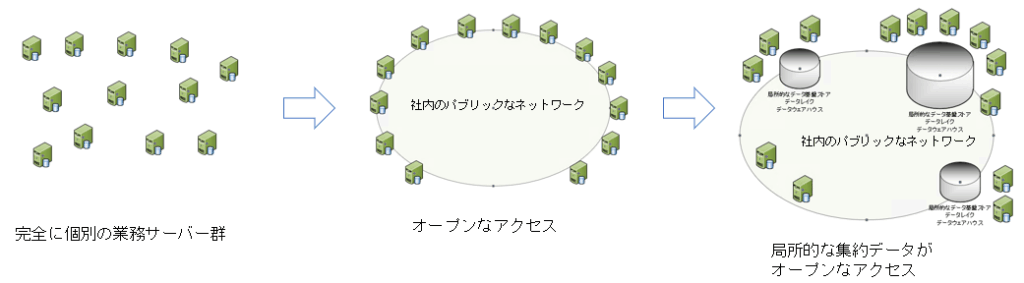
まずはどこにどのようなデータがあるのかを公開し、データを入手可能にします。
しかし、それだけでは、データの品質処理、集約処理、意味統一処理など、データ準備のフェーズを解決できません。それらを解決するために、用途が近いデータ同士で1か所に集められ、徐々に集約してきます。
注意点:
成熟度をあらかじめ認識し、次のステップを全社で共有する事。
データ集約フェーズでは、重複したデータがほぼ確実に発生するため、データソースを明示するようにポリシーを定めること
この組成の仕方は、非常に効率的にデータ基盤を作ることができます。本記事では次のページ以降、これを基にして説明します。
完全集約コース
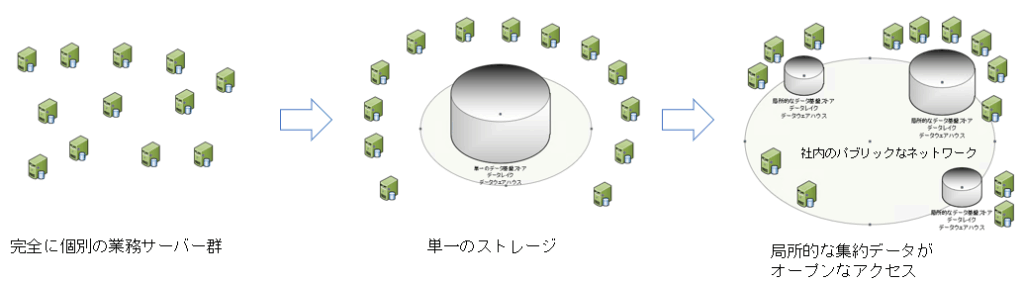
まず、データを1か所に集めます。しかし、ほとんどの場合、この時点で無理が出てくるため、「必要なデータのみ」という限定的なデータ収集になるかもしれません。また、共通マスタや共通 DWH のような「共通データ」という思想に取りつかれます。
しかしながら、業務の多様性の現実の前に、データ基盤は思ったようなサービスを提供することはできません。
その結果、各利用者は、足りないデータを補うように、また、業務ドメインに特化した独自の共通データをこしらえるようになり、それぞれで集約ストレージが生まれて主役が移っていきます。
最終形の設計を考えていないことがポイント
これは、体験から来るアンチパターンですが、最終形を考えていながら、その設計を書かないこともぽいんとです。これを聞くと、「なんだと!?」と突っ込みたくなると思います。
最終形は、チーム内メンバー間の思想の違いにより、かならずブレます。分散型に固執する人や、集約型に固執する人、データ活用の考え方の違いなど様々です。そのため、設計をするとその設計自体ブレて決まりません。
なので、設計やグランドデザインの中に、現実に直面した結果自然に安定した形になる (移れる) ような拡張性を持たせておきながら、そのチーム内で合意しやすい設計で進めて、現実を見ながら最適解に遷移していくほうが良いかと思います。


コメント