
先の記事でデータ基盤のアーキテクチャに集中型ではなく分散型を選定しましたが、規模の考え方や分岐点について補足します。
今回扱う会社規模が「多事業複合体のグローバル企業」としているため、一方的に決めていましたが、実際にはこのような基準があります。
データ統合方式の判断基準
1. データ利用パターン(最優先)
集中型を選ぶべき場合:
- 複数システムのデータを組み合わせた分析が頻繁
- 履歴データの長期保存・分析が必要
- BIツールでのセルフサービス分析が主要用途
- バッチ処理での大量データ処理が中心
分散型を選ぶべき場合:
- リアルタイムでの最新データアクセスが必要
- 単一システムのデータ参照が多い
- データの鮮度が重要(在庫、価格など)
- アドホックなデータ探索が中心
2. パフォーマンス要件
応答時間:集中型は事前処理により高速なクエリが可能、分散型はリアルタイム性に優れるが結合処理で遅延の可能性があります。
同時接続数:集中型は専用インフラで大量アクセスに対応しやすく、分散型は業務システムへの負荷を考慮する必要があります。
3. データガバナンス要件
データ品質管理:集中型では統一的なクレンジング・標準化が可能、分散型では各システムのデータ品質に依存します。
セキュリティ統制:集中型は単一のアクセス制御で管理可能、分散型は各システムの権限管理との整合性が必要です。
4. 運用コスト・複雑さ
ストレージコスト:集中型はデータ重複によるコスト増、分散型はネットワーク転送コストが発生します。
運用負荷:集中型はETL処理の運用管理、分散型は各システムとの接続維持が必要です。
推奨される判断の優先順位
1. コスト・リソース制約:初期投資と運用コストのバランス
2. 業務要件の明確化:リアルタイム性 vs 分析処理の比重
3. 既存システムの制約:APIの有無、性能影響の許容度
4. データ量とアクセス頻度:ネットワーク負荷の実現可能性
5. ガバナンス要件:規制対応やデータ品質基準
全体で一つではなく、部分部分でも適用されるイメージを持つ
使用するデータや要件は1種類ではありません。ほぼ確実にハイブリッド型になるはずです。
たとえばこの通りです。
- マスターデータや履歴分析用データ:集中型
- リアルタイム参照や業務連携:分散型
- 重要度の高いデータから段階的に集中化
私が今回取り上げた前提となる組織は、大規模でコングロマリットな組織を前提にしています。
システムもポリシーも顧客も多様性があるため、全体では分散型になります。
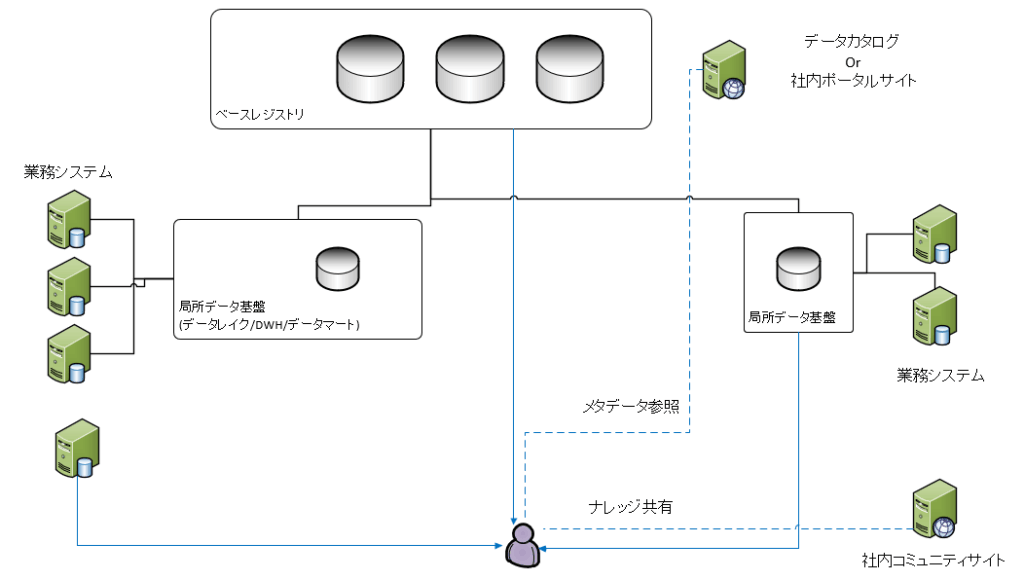
一方、下記の要因で、局所的な集中型データ基盤が出来上がります。
・マスターなど集中管理するものがあるため、このためのベースレジストリという局所的な集約型データ基盤がある
・海外現法や独立した事業では、その域内でデータがやり取りされ、域外との転送や結合のほうが少ないため、局所的に集中型データ基盤ができる
・本社 (グループ内のホールディングス等の投資会社) のあるところでは、グループ会社すべてのデータを集め、経営判断に使う基盤を作る場合、局所的な集約型データベースが作られる。
以上の理由により、これらの局所的な集約型データ基盤が複数できて、それらが分散配置するイメージになります。


コメント