データ基盤全体では分散型であっても、局所的には集約型であることがほとんどです。
特定の事業や部門のように小さい範囲だけを考えるなら、データを1か所に集約することはデメリットよりもメリットの方が大きいと言えます。
例えば、ベースレジストリや局所データ基盤では、データを使いやすくするよう各システムからデータを集め、システム差異を吸収し意味を統一した集約テーブルや DWH を構築していきます。
ここでは、[データ集約] は単にデータを 1 か所に置くことではなく、データを抽象化・高度化し、後述する DWH、エンタープライズ マスタを見据えた集約に関する話をします。
集約レベル
データの収集と言っても、以下のように様々なレベルが存在します。
- 1か所に置くだけ
- データ間で突合できるよう互換させた状態にする
- データの意味統一し、システム間のデータを統制する
単に1か所にありのままのデータを置くだけなのか、中身を考慮して分析可能なDWHを作るのかで難易度は大きく異なります。1箇所に集めるだけなら共有フォルダを用意するだけでよいですが、DWHを作るに至っては、関連組織で共有する概念データモデルの作成も必須となります。
なお、データ集約時に構成するレイヤーと詳細については、別途改めてDWH作成の話で解説いたします。
データ集約を行うステップ
原始人のレベルから文明人のレベルにいきなり飛躍することは難しいものです。多くの外部ベンダーが、データレイク、DWH、データマートの形とHub & Spokeの連携基盤を見せつけ「これが今回構築すべきアーキテクチャです、さあ必要なリソースの導入を進めましょう」とドヤ顔をしますが、私はこれは間違いだと提唱します。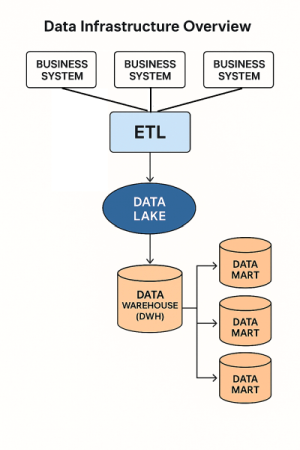
完成に向かうまでにすること、考えること、解決すべき課題が思っているよりもはるかに大きく、すべての解決まで待つことはできないからです。実際のステップとしては、以下の順序で進めることが重要です:
- DB, フォルダの公開
- データの収集
- データの集約
Step 1: DB・フォルダの公開
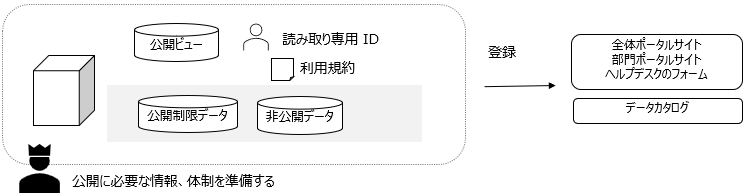
このフェーズは、データを集約せず分散したままにする場合も共通です。
各部門が保持しているデータへのアクセス方法を公開し、共有します。扉を開いてもらう状態です。
この時点で、利用者と提供者双方にデータソース目録のようなものが必要になることが認識されます。いわゆるデータカタログです。
データカタログ、データ分類とアクセス制御、データオーナーという考え方がこの段階で整備されます。この時点で組織におけるデータの民主化が開始されます。
Note:
多くの会社がこのステップを省き、コンサルタントが示した構成を実現するためデータ収集を急ぐあまり、データの民主化について回る「データ公開範囲に関するジレンマ」「データに関する問い合わせ先」「データの帰属意識」の問題を浮き彫りにしてしまいます。これらのフェーズは後で考えるものではなく、自然な進化の中で芽生えさせるものです。
Step2: データの収集
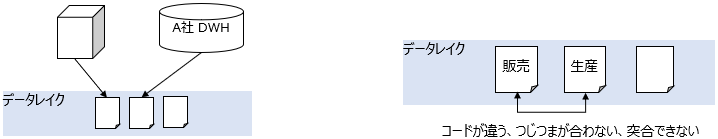
各部門が扉を開いてもらった状態からデータを1か所に集めます。いわゆるデータレイクです。
データのロケーションとシステムからデータを引きはがします。
簡易的にやるなら共有フォルダでもかまいません。
この段階で、「雑多なデータを置いてはならない」「公開した情報の鮮度や説明は必ずカタログに記載する」といった公開データに関するポリシーができます。また、複数システムのデータが公開されることで、システム同士のデータを掛け合わせた利用が活発になりますが、その時に発生するローカル管理のコード同士の変換や不整合、標準化 (後述) の話も出てきて、それぞれのシステムで個別対応が始まります。
各部門は、Step1 時点での度重なるデータ提供の依頼やアクセス方法への問い合わせから解放されたいという心理も Step2 への自然な推進力になります。
Step1 からの変遷であることから分かる通り、データレイクはエンタープライズで一つではなく、局所データ基盤ごとに多数できるイメージになります。
Step3: データの集約

標準化されたデータを基に DWH を構築します。
DWH 作成に先立って、ビジネスとユースケースを基に概念データモデルを作成する必要もあるでしょう。
DWH には事業やドメインに合わせて複数できるものと、ベースレジストリとして機能する共通マスタ、社内事務系の明細データ等があります。
Step2 の段階でシステム間のデータを突合できるようになると、データの品質とコード変換の問題が顕著になってきます。DWH はこの問題も排除し、毎回発生していた準備作業を極力減らすことも解決策に含んできます。
後述しますが、この段階の標準化処理では、各ソースシステムの協力が必要になります。Step2 を経ずにこの段階に来ると、標準化の段階で頓挫します。
成熟度の例
[進め方に関する重要な補足] で述べた通り、データ共有の成熟度レベルを定義し、現状がどうなのか、次に向かうのがどのステップなのかを意識させることが大切です。
| 成熟度Lv | 状況 | 次のステップへのアクション |
| 1 | ユーザー/部門は個別にデータを保持している | サイロ化されたデータを公開するため、データを仕訳ける。公開するデータについては、アクセス方法とデータ仕様をデータカタログに情報を登録する。 |
| 2 | データの場所が公開され、アクセスする方法が周知されている | データ仕様に対する問い合わせに対応しながら、細かい分類仕分けを確認する。公開制限のあるデータは、受け付け方を決める。 |
| 3 | データの所有者により、公開適切なデータと公開しないデータが仕訳されている | 会社内で定められた一元化フォルダへの配置を確認する。出力したデータに誤りがない事、カタログで宣言した通りで配置する。もっとも人気の高いデータから順次対応する。複数のデータ間でコードが統一されるよう、変換テーブルを用意する。標準のフォーマットで配置する。 |
| 4 | データまたはデータ所在に関する情報(メタデータ)が1か所に集まっており、どのデータが正であるか定義されている | 同一の意味を持つ項目が、同一の列挙体になるよう統一し、データを集約する。データ収集単位 (会社ごと、日次、月次等) を定義し、収集単位に対して不足・重複が無い状態を維持する手段を用意する。 |
| 5 | データの更新状態が管理されている。データの意味が統一されている | 利活用状況、不正利用を監視する。 派生ブランチのデータセットとして、ビジネス要求に合わせたデータマートを作成する。 ※ 個別のデータマートは先にできている場合がほとんどである |
Step1 ~ Step3 で各部門に出てくる自然な推進力も意識してください。その推進力を生かすために、次のステップを示しておくのです。
道は示すが、進む速度と進むタイミングは本人達にある程度任せる。
進捗度合いの異なる者が混在した体制を常に受け入れるよう心掛けてください。

コメント